
Papers on storage compute disaggregation

Introduction
Decoupling storage and compute has cost benefits. In essence, this means that the compute nodes do not store all the state and offloads the state to a block store like AWS S3 or Azure blob storage. Decoupled storage has been used in several products in the last couple of years. There are common challenges and advantages that come with this architecture, and the approaches taken to solve them are very similar across many systems. Below is a simplistic view of this pattern.
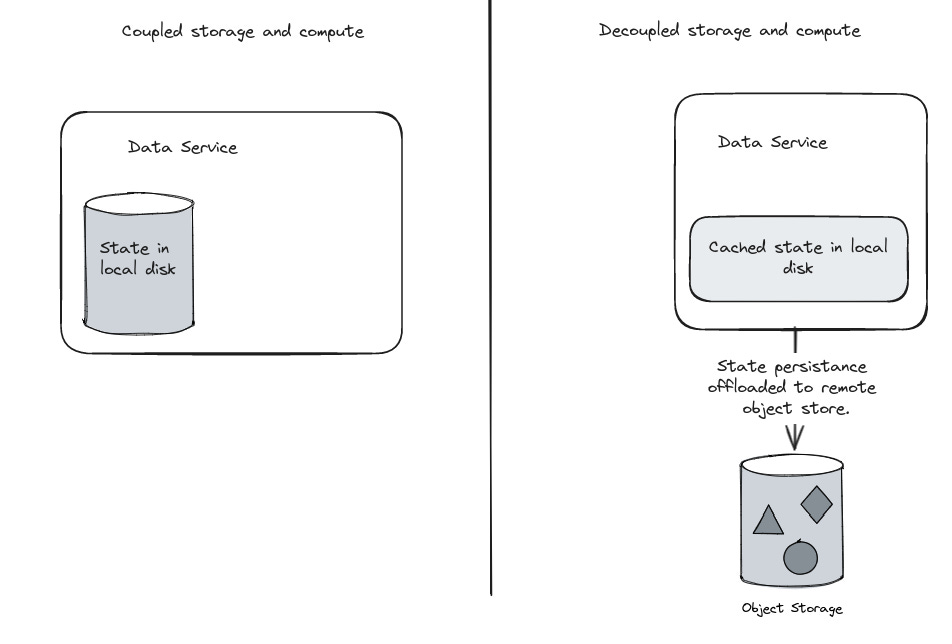
Tiered storage is a variant where there is still some state that is stored locally, while majority of the data is offloaded to object storage. In this post we will look at few papers that describe how different systems implemented decoupled storage.
Disaggregating RocksDB : A Production Experience
Rocks DB serves as the store for several applications in Meta. Added latency due to decoupled storage is acceptable for a lot of applications. The paper talks about changes done to Rocks DB to use Meta’s object store (Tectonic) instead of local SSDs. It is still beneficial to stick to RocksDB as the interface, since there is wide spread adoption inside Meta and a large open source community.
RocksDB context
Log structured merge tree (LSM) based.
Buffers in memory, uses write ahead logging(WAL) and flushes immutable SSTables to disk.
Compacts smaller SSTables to larger ones asynchronously.
Tectonic supports append only files and reads at an offset. Teconic can use epoch fencing to enforce exclusive write access to suite RocksDB’s needs. These properties of tectonic, and the immutable nature of RocksDB files made this possible.
Here are some of the changes described in the paper.
A new storage device implementation targeting Tectonic.
Different failure handling.
Smaller timeouts for GET, larger timeout for background operations like compaction. Previously IO failures marked the DB read-only, with remote store, failure rate increases and additional retries are beneficial.
Dynamically adjusting the timeouts at runtime.
Hedged writes and hedged reads after a small delay.
Parallel IO, read-ahead with exponential increase of read-ahead size.
Caching
Local SSD cache for data files.
Metadata cached locally.
Different redundancy schemes for WAL vs Data files configured in tectonic.
With the changes described, they are able to use it in production for several use cases including ZippyDB, a sharded key-value store that uses RocksDB.
In addition to reduced cost, here are the other benefits.
Recovery after a compute node failure is faster, compared to a full node rebuild previously.
Read only replica can be served by a different instance.
Background operations such as backup and compaction can be offloaded to other services, and primary can be freed up.
Amazon Aurora Papers
Amazon Aurora initially hosted DB files on Elastic block store. There were replicas as well. This caused write amplification, since data is replicated inside EBS as well as with secondary instances.
These two papers talk about how aurora’s design was changed to split the storage into separate nodes.
Design considerations for high throughput cloud-native relational databases.
Amazon Aurora: On avoiding distributed consensus for I/Os, commits and membership changes.
Key idea is that pages are grouped into segments, and stored in a quorum of storage nodes. Segments are roughly about 10 GB in size. Redo logs are sent to a set of storage nodes, and the requests are acked after there is a quorum. Storage nodes gossip to fill holes in their log. Storage node’s state is periodically snapshotted to S3. While storage nodes are still stateful, and holds data, this design refactored the database into distinct compute and storage services.
Socrates: The new SQL server in cloud follows a similar design. It separates log as a different service, and page servers read from the log service. Several components of SQL server such as Resilient buffer pool extension and remote block io were reused, and the design split the server into separate services. Buffer pool of compute nodes query page servers when pages are not available locally.
Operations such as backup are offloaded to storage servers in both the cases.
Neon - Serverless PostgreSQL follows a similar design as Aurora and Socrates. This post by Neon captures the architectural decisions related to storage-compare separation and this post provides a more detailed version. Few interesting aspects from these posts are
Like Socrates, page service and WAL service are different. This also different hardware choices and separation of concerns.
Use of Paxos to select the primary PostGreSQL compute, have a quorum of WAL service nodes and page servers as learners.
Multi-tenant storage services, enabling economy of scale, scale-to-zero and reduced cold start time.
Other examples
SlateDB: An embedded key-value store built on object storage. It is a rust library that batches writes to reduce put calls on S3 and supports advanced features such as detached compactor, writable clones, read-only secondary and more.
MotherDuck: DuckDB in the cloud and in the client stores the data in S3, and maps single file byte range IO requests to S3 files.
Delta lake data files and metadata files are immutable, and this is leveraged in data bricks as per the paper. It caches files on local SSD and by nature treats object store as its only store.
StarTree added tiered storage for Apache Pinot. This enables users to retain more data without a significant increase in cost. Examples latency numbers showed 5 to 10 times latency increase, but were still 400 ms.
Conclusion
In conclusion, decoupling of storage and compute presents cost benefits and operational advantages for various systems. Leveraging immutable nature of certain data objects, offloading background processing, recovery time improvement, tiered storage, adaptive timeouts are some of the techniques that we looked at through these papers.