
Paper notes: State management in stream processing Systems

Stateful stream processing requires taking checkpoints of the state for recovery from failures and for scaling out the processors. State could be the result of all the tuples seen from the beginning of the processing, and not just based on the last few tuples in a temporal window. i.e. State is a function of entire history of all the tuples the processor has every seen. This post would look at the following papers related to checkpoints in stream processing systems. Together, they provide good understanding of the problem statement and approaches.
Determining global states of distributed systems (Chandy Lamport algorithm) - classic paper on distributed snapshots.
State Management in Apache Flink - describes Flink’s aligned checkpoints design.
Unaligned checkpoints in Apache Flink - improvements to deal with back pressure, which affects checkpoint frequency.
Log based incremental checkpoints in Apache Flink - another technique to speed up checkpoints.
Integrating scale out and fault tolerance in stream processing using operator state management.
Winner of 2023 SIGMOD test of time award. This paper provides a set of primitives for managing checkpoints on an abstract stream processing systems. Techniques described in this paper are more decentralized, compared to the globally co-ordinated state in (1) and Flink’s approach in (2), (3) and (4).
We will use a variation of query 4 from nexmark benchmark as the running example throughout the post.
Query Definition:
Auction stream is an unbounded sequence of [auctionId, category, SellerId, auctionStartTime, auctionExpiryTime]. Bid stream is an unbounded sequence of [buyerId, auctionId, bidTime, bidPrice].
Current winning bid is the one that has the maximum bidPrice seen for an auction. Note that winning bid for an auction could change during the auction time. The query produces two output streams.
Average of current winning bids for every category. Since winning bid for an auction could change and because there would be new auctions, average per category would change over time.
Stream of auctions that had more than 10 bids during its lifetime.
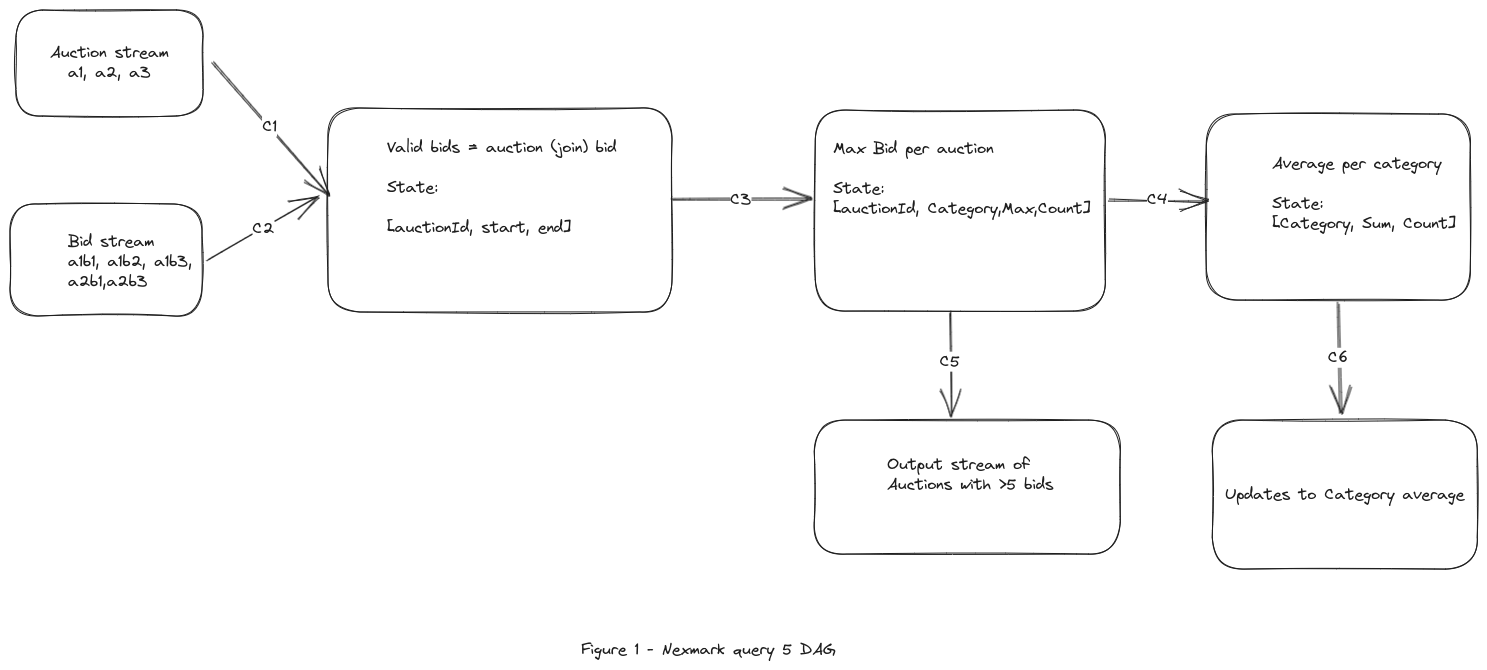
This diagram shows shows the query DAG and what would need to be in the state. Auction stream and Bid stream would be external persisted message queues.
Determining global states of distributed systems
This paper first focuses on the properties of the global state. One of the key property is that, if S* is a state in the snapshot, then i) S* is reachable from initial state. ii) It is possible to reach terminal state from S*.
Snapshot includes state of all the processors (boxes in Figure 1) and channels (edges in Figure 1, for example C1).
Here is a screenshot from the original paper that describes the algorithm.

Lets look at how this applies to the join processor.
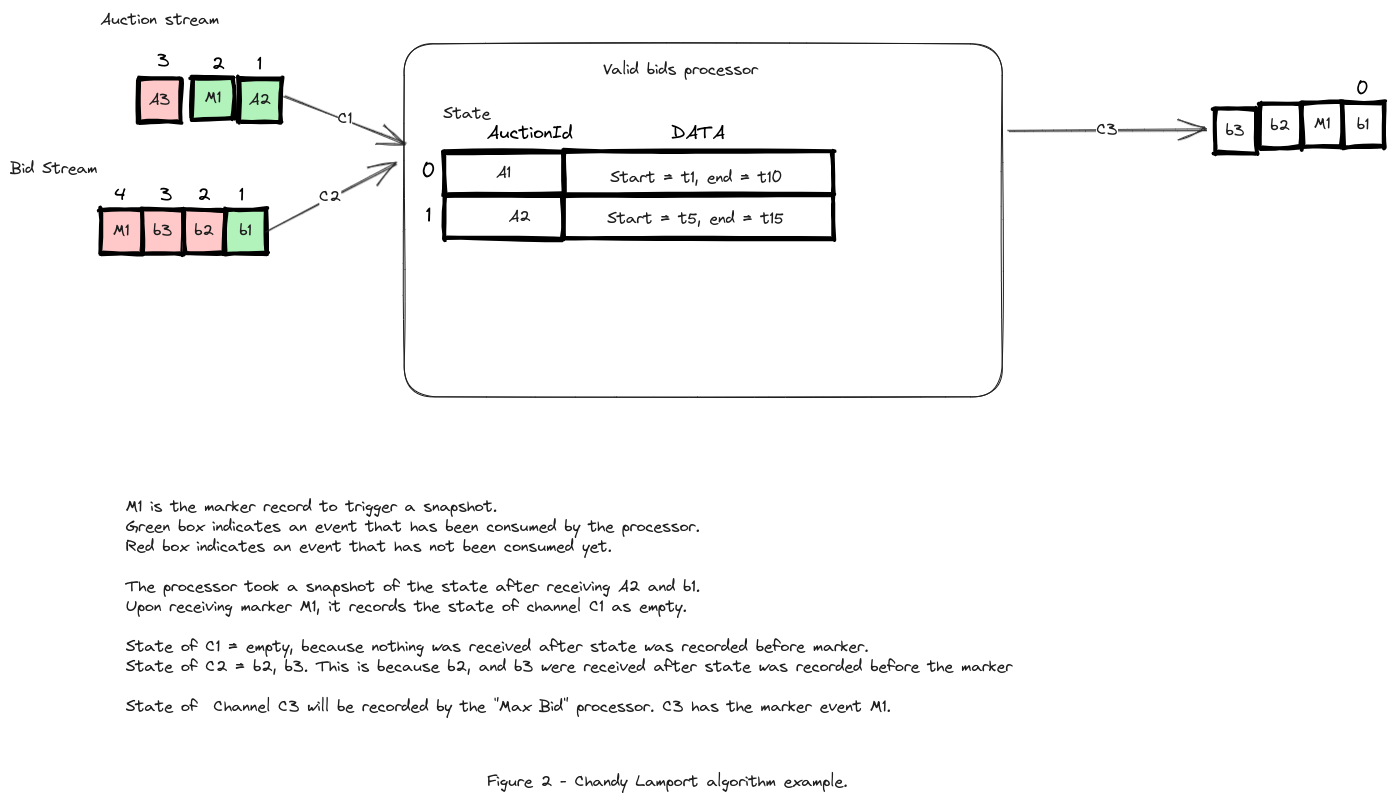
Marker event propagates through the DAG, and states of all the processors and channels are recorded. The state that is assembled from all these pieces represents a consistent global snapshot and holds the properties shared earlier.
State Management in Flink
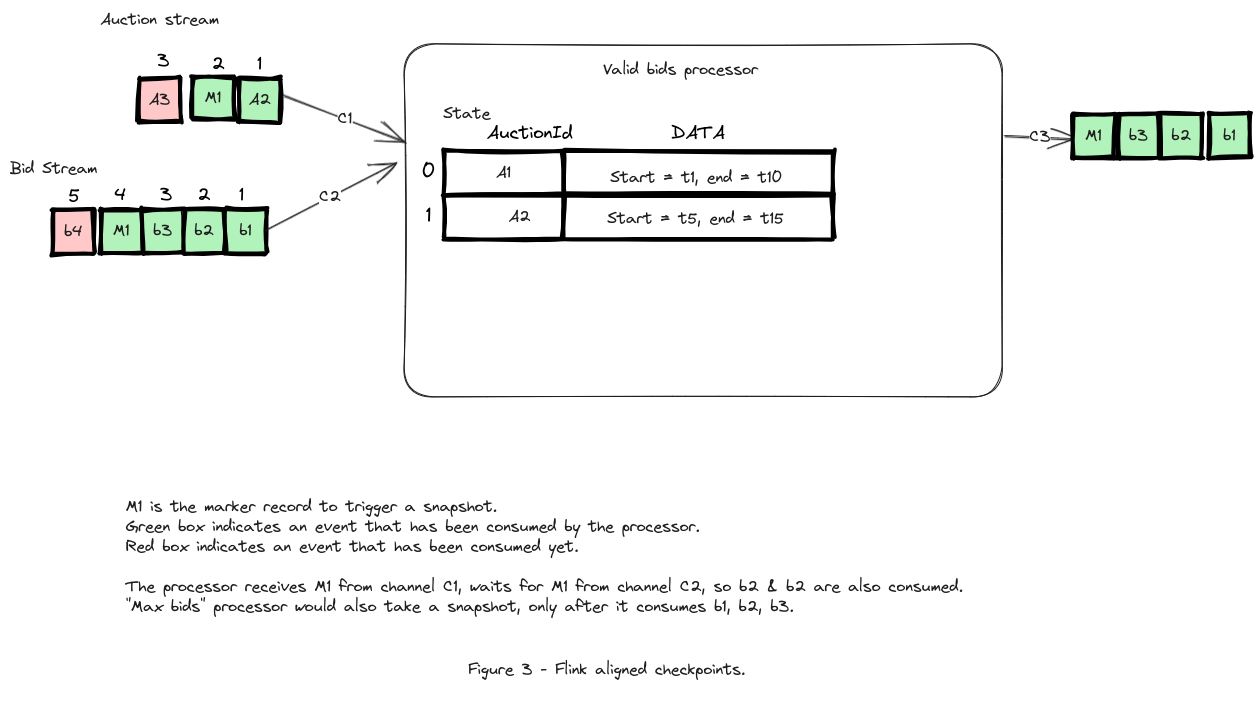
This paper describes how checkpoints are taken in Flink. It describes the additional components, such as a component to send markers along all the input channels and the algorithm.
The difference to what is described in the Chandy-Lamport section is that, processor blocks the channel along which it received the marker event, until it gets the marker event from all input channels. This is called as “Aligned Checkpoints”. Advantage of this approach is that, channel state is empty in the snapshots and only processors have their state stored. Disadvantage is that it needs to wait for the marker event, and cannot receive additional events. If the data rate is high in one of the input channels, it would delay the checkpoint frequency. Another aspect here is that the checkpoints are always global, i.e. every checkpoint has state for all the processors. Checkpoint flow in Flink is described in Figure 3.
Updates and improvements
“Unaligned Checkpoints” is a change to increase the checkpoint frequency in the presence of back pressure and variable rate streams. It is closer to Chandy-Lamport algorithm, and includes input buffers and output buffers (i.e. Channels) in the snapshot. A drawback of this approach is that size of the checkpoint increases, with inclusion of buffers in addition to just the processor state.
A second improvement is to do a better incremental and continuous IO. Write ahead log of the state store is continuously stored in remote store, this reduces the IO that needs to be done during checkpoint. The snapshot can then be compacted asynchronously.
Integrating scale out and fault tolerance in stream processing using operator state management.
In the previous approaches, snapshot was global. This paper describes an approach where every processor independently checkpoints and informs the other processors. In addition, detailed aspects of recovery and re-partitioning the state were not described in the first two papers. Those primitives are covered well in this paper.
State has the following components
Processing state: This is the operator state, similar to the previous sections. The state in addition includes the last logical timestamp ingested.
Buffer state: Processors have output buffers and downstream processors consume from these. Tuples that are not consumed by the downstream processors becomes part of the buffer state.
Routing state: Same mechanism is used for both recovery from faults as well as for scaling out. So, the paper describes a partitioning scheme for the state and this routing state is the mapping from key range to downstream processor partition responsible for the key range.
Upstream processor is informed of the checkpoints by downstream processor, and after that buffer state of the upstream processor changes. Recovery of each processor is independent, and it (re-)sends the tuples in output buffer. They are attached with a logical timestamp, so downstream can ignore the ones that it has already consumed. As we see, decision to checkpoint is not controlled centrally and there is also no single “snapshot” that is globally valid.
Below figure describes the state for our running example.

In this post, we looked at papers that describe different approaches to create checkpoints in stream processing systems using auction management as a running example.