
Notes on two Presto papers

Previous post covered different kinds of data systems in the analytical toolbox for a company. Interactive queries are necessary for several use cases. Presto is an open source federated SQL query engine. This post summarizes two papers related to Presto.
Presto: SQL on Everything => Initial paper on presto, covering its design.
Presto: A Decade of SQL analytics => Published in 2023. Covers changes to presto.
Use cases
Presto started as a SQL engine to support interactive queries on a variety of data sources. It has since then expanded to support more use cases. Meta’s initial use cases for Presto were interactive analysis and advertiser analytics. Advertiser analytics exposed an interface that generated restricted set of query shapes. Uber had a similar use case, for ad-hoc exploration in uber eats ops automation. In both these cases, presto is used as the backend for an application as opposed to just direct query by internal users. Extensibility is one of the key aspects of Presto. As we saw in the previous post, Uber leveraged Presto to add SQL support for Pinot by adding a Pinot connector in Presto.
Architecture & System Design
Presto’s architecture is a set of workers processing different parts of the query, keeping the intermediate results mostly in-memory. Execution is pipelined. Extensibility is provided through plugins. Connectors are written as plugins as well. Documentation lists more than 30 connectors as of 2023, including delta lake and iceberg connectors.
This image summarizes the architecture and system design section.
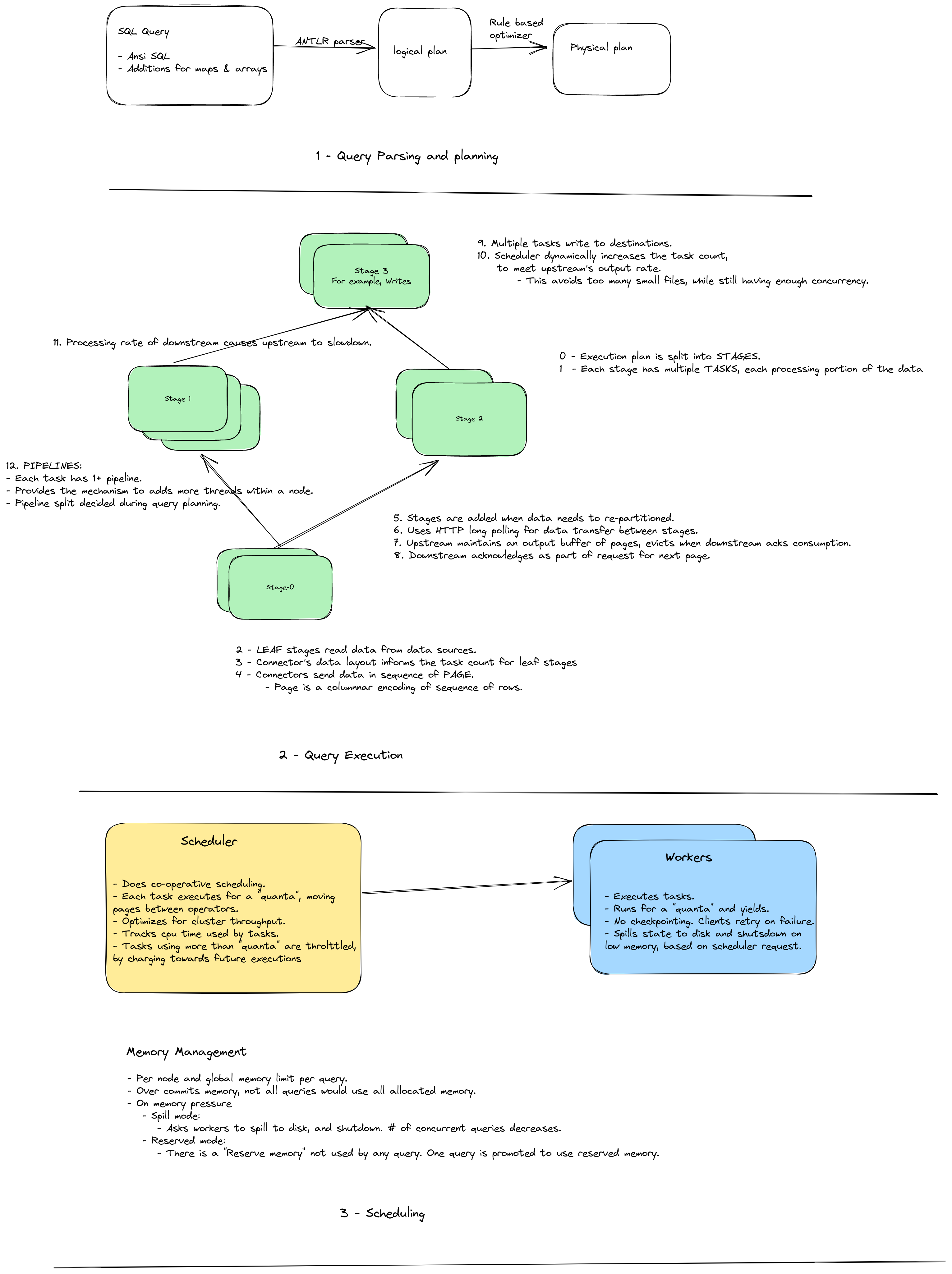
Architecture evolution
Increase in data sizes, adoption and newer use cases required changes to Presto’s architecture. Here are some of the changes described in the second paper.
Multiple coordinators: Single coordinator was a single point of failure, and did not scale with the increase in number of queries, and direction to move to smaller containers. With multiple coordinators, queries go to a random coordinator.
Caching: Multiple levels of caching was added. Raw data, fragment result from leaf nodes and metadata is cached. Query canonicalization followed by hashing query fragment to the same worker results in faster processing of repeated similar queries.
Native execution: Velox, a C++ library is used for execution instead of JVM. This results in significant speed up.
Optimizer improvements:
Cost based optimizer using statistics stored in metadata store.
History based optimizer: Persist real statistics from previous runs and use that instead of estimation.
Adaptive execution: Use statistics from upstream during the run to re-optimize downstream dynamically.
Disk spilling: Beyond a limit, data is offloaded to disk, to reduce memory usage.
Materialized view is the other interesting part covered in the second paper. When a user creates a materialized view, periodically, whenever a new partition is sealed (for example, say a day level partition is added), a job computes the results of the materialized view and persists it. During query time, the query is rewritten as the union of results from persisted data and the new data added since previous materialization. Paper does not describe if the materialized view computation is incremental or if it is a full rerun. When a materialized view is present, queries are also rewritten to use the materialized view instead of the original table to speed up processing.
Presto on Spark is the other major aspect covered. This gets rid of Presto’s task scheduling. Instead, Presto query is rewritten as Spark RDDs and execution is done by launching Presto as a library from spark worker. Spark takes care of resilience and shuffle. Spark SQL is being replaced with Presto on Spark gradually inside meta.
Additional capabilities, such as graph extensions, user defined types, udf service and mutability using “delta” were also added over time.
That is it for today’s post. These two papers describe the initial design of Presto, gaps with initial architecture as use cases evolve and how they were addressed.